IntraSiteInterpolation#
- class uniharmony.interpolation.IntraSiteInterpolation(interpolator: str | Literal['smote', 'borderline-smote', 'svm-smote', 'adasyn', 'kmeans-smote', 'random'] | SamplerMixin = 'smote', interpolator_kwargs: dict | None = None, random_state: int | RandomState | None = None, balance_strategy: str | Literal['per_site', 'global_max'] = 'per_site', n_bins: int | None = 10, binning_strategy: str | Literal['uniform', 'quantile'] = 'quantile', task: str | Literal['auto', 'classification', 'regression'] = 'auto')#
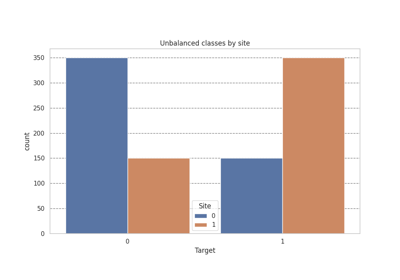
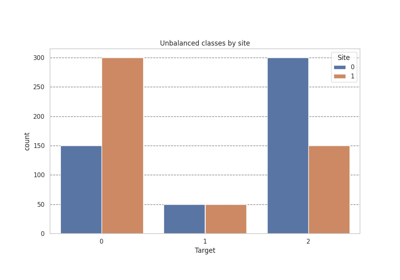
Intra-Site Interpolation (ISI) Harmonization.
This sampler performs site-wise class balancing to reduce spurious correlations between site membership and class labels.
For each site independently: - The target class count is determined by
balance_strategy. - All minority classes are oversampled to match the target count. - Any imblearn-compatible oversampling strategy may be used. - Alternatively, all classes in the smaller sites are oversampled to matched the biggest site.When covariates are provided, balancing is performed within each covariate stratum (unique combination of covariate values) within each site, preserving the joint distribution of covariates and target labels.
For regression tasks, the continuous target is binned into discrete intervals and each bin is treated as a class for balancing purposes.
- Parameters:
- interpolatorstr or SamplerMixin instance, optional (default “smote”)
The interpolator to use. Can be a str specifying a built-in method or an instance of SamplerMixin. Supported str methods are:
“smote”: Synthetic Minority Over-sampling Technique
“borderline-smote”: Borderline-SMOTE
“svm-smote”: SVM-SMOTE
“adasyn”: Adaptive Synthetic Sampling
“kmeans-smote”: KMeans-SMOTE
“random”: Random Over-Sampling
- interpolator_kwargsdict or None, optional (default None)
Additional keyword arguments passed to
interpolator.- random_stateint or RandomState instance or None, optional (default None)
The seed of the pseudo random number generator or RandomState for reproducibility.
- balance_strategy{“per_site”, “global_max”}, optional (default “per_site”)
Strategy to determine the target count for oversampling:
“per_site”: Each site is balanced independently to its own majority class count.
“global_max”: All sites are balanced to the global maximum class count across all sites. Both minority and majority classes are samples to match the N for the majority class across sites.
- n_binsint or None, optional (default 10)
Number of bins for regression target binning.
- binning_strategy{“uniform”, “quantile”}, optional (default “quantile”)
Strategy for creating bins when the task is regression:
“uniform”: Bins of equal width covering the target range.
“quantile”: Bins with approximately equal number of samples.
- task{“auto”, “classification”, “regression”}, optional (default “auto”)
Task type. If
"auto", inferred fromydtype (integer types imply classification, floating types imply regression). A regression problem is treated as a multi-class classification problem.
- Attributes:
- sites_resampled_ndarray of shape (n_samples_new,)
Site identifiers for the resampled dataset.
- samples_created_dict
A nested dictionary mapping
{site: {class_label: n_created}}, wheren_createdis the number of synthetic samples generated for that class in that site. For regression,class_labelis the bin index.- target_count_int or None
The target sample count per class used for balancing. Set to the global maximum when
balance_strategy="global_max", otherwiseNone(targets are per-site).- bins_ndarray or None
Bin edges used for regression target binning.
Nonefor classification tasks.- task_str
Inferred or specified task type (“classification” or “regression”).
Methods
fit(X, y, **params)Check inputs and statistics of the sampler.
fit_resample(X, y, sites, *[, ...])Fit and resample the dataset using site-wise interpolation.
get_metadata_routing()Get metadata routing of this object.
get_params([deep])Get parameters for this estimator.
set_fit_resample_request(*[, ...])Configure whether metadata should be requested to be passed to the
fit_resamplemethod.set_params(**params)Set the parameters of this estimator.
- fit_resample(X: ArrayLike, y: ArrayLike, sites: ArrayLike, *, categorical_covariate: ArrayLike | None = None, continuous_covariate: ArrayLike | None = None, n_bins_cont_cov: int | None = None, binning_strategy_cont_cov: str | Literal['uniform', 'quantile'] = 'quantile') tuple[ndarray[tuple[Any, ...], dtype[_ScalarT]], ndarray[tuple[Any, ...], dtype[_ScalarT]]]#
Fit and resample the dataset using site-wise interpolation.
- Parameters:
- Xarray-like of shape (n_samples, n_features)
Feature matrix containing the input samples.
- yarray-like of shape (n_samples,)
Target values. Integer labels for classification, continuous values for regression.
- sitesarray-like of shape (n_samples,)
Site or domain identifiers indicating the origin of each sample. Resampling is performed independently within each site.
- categorical_covariatearray-like of shape (n_samples, n_categorical), default=None
Categorical covariates used for stratified balancing. When provided, classes are balanced within each unique covariate combination within each site.
- continuous_covariatearray-like of shape (n_samples, n_continuous), default=None
Continuous covariates used for stratified balancing. Samples are grouped by approximate matching within
covariate_tolerance.- covariate_tolerancearray-like of shape (n_continuous,), default=None
Maximum allowed absolute difference for continuous covariate grouping. Must have one value per continuous covariate column. If
None, exact matching is required.- n_bins_cont_covint or None, default=None
Number of bins to use for continuous covariates when creating groups. If None, no binning is applied and exact matching is used for grouping.
- binning_strategy_cont_cov{“uniform”, “quantile”}, default=”quantile”
Strategy for binning continuous covariates when creating groups: - “uniform”: Bins of equal width covering the covariate range. - “quantile”: Bins with approximately equal number of samples.
- Returns:
- X_resamplednumpy.ndarray of shape (n_samples_new, n_features)
The feature matrix after site-wise oversampling.
- y_resamplednumpy.ndarray of shape (n_samples_new,)
The corresponding targets after resampling.
- Raises:
- ValueError
If
X,y, andsiteshave incompatible shapes, if fewer than two unique sites are present, if any site is missing any class, or ifbalance_strategyis invalid.
Notes
Sites can be retrieved from IntraSiteInterpolation.sites_resampled_
- set_fit_resample_request(*, binning_strategy_cont_cov: bool | None | str = '$UNCHANGED$', categorical_covariate: bool | None | str = '$UNCHANGED$', continuous_covariate: bool | None | str = '$UNCHANGED$', n_bins_cont_cov: bool | None | str = '$UNCHANGED$', sites: bool | None | str = '$UNCHANGED$') IntraSiteInterpolation#
Configure whether metadata should be requested to be passed to the
fit_resamplemethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config()). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed tofit_resampleif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it tofit_resample.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
- Parameters:
- binning_strategy_cont_covstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
binning_strategy_cont_covparameter infit_resample.- categorical_covariatestr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
categorical_covariateparameter infit_resample.- continuous_covariatestr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
continuous_covariateparameter infit_resample.- n_bins_cont_covstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
n_bins_cont_covparameter infit_resample.- sitesstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sitesparameter infit_resample.
- Returns:
- selfobject
The updated object.